執筆途中。あくまでメモなので注意
Pytorchの並列化について。
GAN等の重たいモデルを学習する際や、バッチサイズを大きくしたかったり、学習を高速で終えるために複数のGPUを使いたいときがあります。
そういった場合「並列処理」を使います。
PytorchにはDataParallel と DistributedDataParallelの2つがあります。DDPを使うと学習が早く終わります。
Improvement of DDP is needed! · Issue #463 · ultralytics/yolov5 · GitHub
面倒なので説明は省略しますが、DPだとPythonのGIL(グローバルインタプリタロック)の制限がボトルネックになって遅い為DDPを使うと早くなります。
CPU
# CPU import torch import torchvision import torch.nn as nn class NN(nn.Module): def __init__(self): super().__init__() self.n = nn.Sequential( nn.Flatten(), nn.Linear(28*28, 128), nn.ReLU(), nn.Linear(128, 10) ) def forward(self, x): return self.n(x) data = torchvision.datasets.MNIST(root= "data", train=True, download=True, transform = torchvision.transforms.ToTensor()) data_loader = torch.utils.data.DataLoader(data, batch_size=64, shuffle=True, num_workers=2, pin_memory=True) model = NN() criterion = nn.CrossEntropyLoss() optimizer = torch.optim.SGD(model.parameters(), lr=1e-3) for epoch in range(2): total_loss = 0 for imgs, labels in data_loader: predict = model(imgs) loss = criterion(predict, labels) total_loss+= loss.item() optimizer.zero_grad() loss.backward() optimizer.step() print(f"{epoch:3d}: {total_loss:.4f}") torch.save(model.state_dict(), 'model.pth')
Single GPU
# CPU
model = NN()
predict = model(imgs)
モデルとデータにcuda()をつけるだけ。
# Single GPU
model = NN().cuda()
predict = model(imgs.cuda())
labels = labels.cuda()
DataParallel
# Single GPU model = NN().cuda() predict = model(imgs.cuda()) torch.save(model.state_dict(), 'model.pth')
modelをtorch.nn.DataParallelで包んであげるだけ。
デフォルトだと見えるGPU全部使うので、GPU番号を指定してください。
# Multi GPU(DP) model = NN().cuda() model = torch.nn.DataParallel(model, device_ids=[0, 1, 2]) predict = model(imgs.cuda()) torch.save(model.module.state_dict(), 'model.pth')
または、python a.pyの前に、CUDA_VISIBLE_DEVICES=0,1,2をつけて見えるGPUを制限するのもいいです。
# Multi GPU(DP) # CUDA_VISIBLE_DEVICES=0,1,2 model = NN().cuda() model = torch.nn.DataParallel(model) predict = model(imgs.cuda()) torch.save(model.module.state_dict(), 'model.pth')
備考として各GPUに送られるバッチサイズは、宣言したバッチサイズ/並列にした個数になります。
また、モデルを保存するときはmoduleを呼び出して上げてください。
理由/忘れた場合 Pytorchのnn.DataParallelを使ったモデルを保存するとloadするときにエラーになる問題 - Qiita
DistributedDataParallel
いくつかあるので分割します。
まず最初におまじないを書きます。
# Multi GPU(DDP) import os rank = int(os.environ["LOCAL_RANK"]) torch.cuda.set_device(rank) world_size = torch.cuda.device_count() torch.distributed.init_process_group(backend='nccl', init_method='env://', world_size=world_size)
world_sizeは並列処理の個数
rankはそのうちの何個目かを示すものです。
.to(rank)
でGPUにデータを送ってますが、ネットのコードを見てみると「4GPUで8並列」とかやってるコードもありました。そういうことをやる場合は
gpu_id = rank % world_size
とか適当な変数付けて
.to(gpu_id)
とかすると良いです。
# single data_loader = torch.utils.data.DataLoader(data, batch_size=64, shuffle=True, num_workers=2, pin_memory=True)
data_loaderはsamplerというものを使います。
各epochの最初でset_epochを宣言することを忘れずに。
# Mult GPU(DDP) sampler = torch.utils.data.distributed.DistributedSampler(data, rank=rank) data_loader = torch.utils.data.DataLoader(data, batch_size=64, num_workers=2, pin_memory=True, sampler=sampler) for epoch in range(100): sampler.set_epoch(epoch)
# single
model = model.cuda()
DataParallelと同じように、ラップしてあげます。
# Mult GPU(DDP)
model = torch.nn.parallel.DistributedDataParallel(model.to(rank), device_ids=[rank])
モデルを保存するときはDP同様moduleを使うこと。
注意点として、何かしらのTensorの値を全GPUで共有したいときは
torch.distributed.all_reduce(tensor)
を使ってください。
tensorに共有された値が入ります。
呼び出し方は
CUDA_VISIBLE_DEVICES=1,2,3,4 torchrun --nnodes=1 --nproc_per_node=4 hoge.py (args1) (...)
です。
参考文献
https://naga-karthik.github.io/post/pytorch-ddp/
torchrun (Elastic Launch) — PyTorch 1.13 documentation
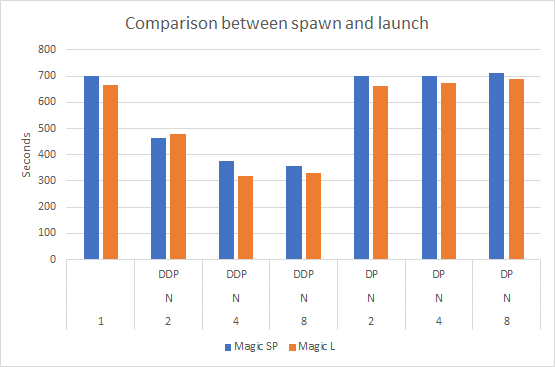
全コード 比較
CPU
# CPU import torch import torchvision import torch.nn as nn class NN(nn.Module): def __init__(self): super().__init__() self.n = nn.Sequential( nn.Flatten(), nn.Linear(28*28, 128), nn.ReLU(), nn.Linear(128, 10) ) def forward(self, x): return self.n(x) data = torchvision.datasets.MNIST(root= "data", train=True, download=True, transform = torchvision.transforms.ToTensor()) data_loader = torch.utils.data.DataLoader(data, batch_size=64, shuffle=True, num_workers=2, pin_memory=True) model = NN() criterion = nn.CrossEntropyLoss() optimizer = torch.optim.SGD(model.parameters(), lr=1e-3) for epoch in range(2): total_loss = 0 for imgs, labels in data_loader: predict = model(imgs) loss = criterion(predict, labels) total_loss+= loss.item() optimizer.zero_grad() loss.backward() optimizer.step() print(f"{epoch:3d}: {total_loss:.4f}") torch.save(model.state_dict(), 'model.pth')
1 GPU
# Single GPU import torch import torchvision import torch.nn as nn class NN(nn.Module): def __init__(self): super().__init__() self.n = nn.Sequential( nn.Flatten(), nn.Linear(28*28, 128), nn.ReLU(), nn.Linear(128, 10) ) def forward(self, x): return self.n(x) data = torchvision.datasets.MNIST(root= "data", train=True, download=True, transform = torchvision.transforms.ToTensor()) data_loader = torch.utils.data.DataLoader(data, batch_size=64, shuffle=True, num_workers=2, pin_memory=True) model = NN().cuda() criterion = nn.CrossEntropyLoss() optimizer = torch.optim.SGD(model.parameters(), lr=1e-3) for epoch in range(2): total_loss = 0 for imgs, labels in data_loader: predict = model(imgs.cuda()) loss = criterion(predict, labels.cuda()) total_loss+= loss.item() optimizer.zero_grad() loss.backward() optimizer.step() print(f"{epoch:3d}: {total_loss:.4f}") torch.save(model.state_dict(), 'model.pth')
複数GPU(Data Parallel)
# Multi GPU(DP) import torch import torchvision import torch.nn as nn class NN(nn.Module): def __init__(self): super().__init__() self.n = nn.Sequential( nn.Flatten(), nn.Linear(28*28, 128), nn.ReLU(), nn.Linear(128, 10) ) def forward(self, x): return self.n(x) data = torchvision.datasets.MNIST(root= "data", train=True, download=True, transform = torchvision.transforms.ToTensor()) data_loader = torch.utils.data.DataLoader(data, batch_size=64*torch.cuda.device_count(), shuffle=True, num_workers=2, pin_memory=True) model = NN().cuda() model = torch.nn.DataParallel(model) criterion = nn.CrossEntropyLoss() optimizer = torch.optim.SGD(model.parameters(), lr=1e-3) for epoch in range(2): total_loss = 0 for imgs, labels in data_loader: predict = model(imgs.cuda()) loss = criterion(predict, labels.cuda()) total_loss+= loss.item() optimizer.zero_grad() loss.backward() optimizer.step() print(f"{epoch:3d}: {total_loss:.4f}") torch.save(model.module.state_dict(), 'model.pth')
複数GPU(Distributed Data Parallel)
# CUDA_VISIBLE_DEVICES={使うGPUのID} torchrun --nnodes 1 --nproc_per_node {使用するGPUの個数} sample.py # CUDA_VISIBLE_DEVICES=0,1 torchrun --nnodes 1 --nproc_per_node 2 sample.py # multi GPU(DDP) import torch import torchvision import torch.nn as nn import os class NN(nn.Module): def __init__(self): super().__init__() self.n = nn.Sequential( nn.Flatten(), nn.Linear(28*28, 128), nn.ReLU(), nn.Linear(128, 10) ) def forward(self, x): return self.n(x) rank = int(os.environ["LOCAL_RANK"]) torch.cuda.set_device(rank) world_size = torch.cuda.device_count() torch.distributed.init_process_group(backend='nccl', init_method='env://', world_size=world_size) data = torchvision.datasets.MNIST(root= "data", train=True, download=True, transform = torchvision.transforms.ToTensor()) sampler = torch.utils.data.distributed.DistributedSampler(data, rank=rank) data_loader = torch.utils.data.DataLoader(data, batch_size=64, sampler=sampler, num_workers=2, pin_memory=True) model = NN() model = torch.nn.parallel.DistributedDataParallel(model.to(rank), device_ids=[rank]) criterion = nn.CrossEntropyLoss() optimizer = torch.optim.SGD(model.parameters(), lr=1e-3) for epoch in range(2): sampler.set_epoch(epoch) total_loss = 0 for imgs, labels in data_loader: predict = model(imgs.cuda()) loss = criterion(predict, labels.cuda()) total_loss+= loss.item() optimizer.zero_grad() loss.backward() optimizer.step() total_loss = torch.Tensor([total_loss])[0].cuda() torch.distributed.all_reduce(total_loss) total_loss = total_loss.item() if rank == 0: print(f"{epoch:3d}: {total_loss:.4f}") if rank == 0: torch.save(model.module.state_dict(), 'model.pth')